Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions
本文是论文Vision-and-Language Navigation: A Survey of Tasks, Methods, and Future Directions的阅读笔记和个人理解,论文由加州大学和阿德莱德大学等单位共同合作而成,发表于 ACL 2022。
论文的全文翻译在本人知乎参考,便于读者快速阅读,以下是本人的阅读笔记和个人理解,如有错误之处,恳请批评指正。
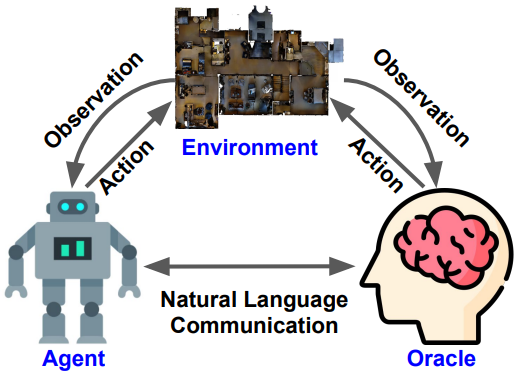
VLN 全称 Vision-and-Language Navigation,是为了构建能够用自然语言与人类交流、感知环境并执行现实世界任务的智能体,一般认为 VLN 需要有三个要素,Environment、Agent and Oracle。
VLN 是 Embodied AI 中的一类,Embodied AI 又是 AGI(Artificial General Intelligence)的一小类,因此 VLN 的研究十分有意义,但是 VLN 将 vision、language 和 action 这三种模态融合到一起,对输入信息的理解要求很高,并且目前数据集较少,比较复杂,实现困难。
首先,VLN 可以极大程度解放人的劳动。例如在家里可以让 agent 帮我们从厨房拿苹果,或者拿个勺子,或者取快递,外卖之类的,或者危险任务,火灾救人,拆炸弹。VLN 是要求人和 Agent 互相合作,在环境中去完成迁移任务,Agent 可以实时传送画面给我们,然后我们可以使用自然语言告诉它接下来应该怎么做。
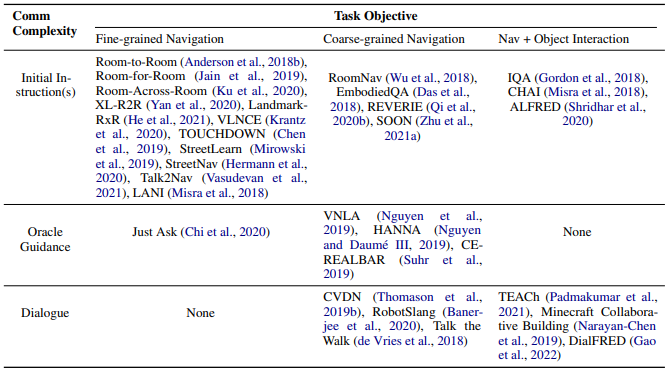
论文将当前数据集分为两个轴第一个是 Communication Complexity 和 Task Objective。
Communication Complexity:
* Initial Instruction:Oracle在一开始的时候给agent一句命令,告诉它去干嘛,后续不再涉及自然语言处理和理解,就是单纯的路径导航。 * Oracle Guidance:agent在接收到初始命令之后,如果感到困惑,仍然无法完成目标任务,我们再告诉它应该怎么做,向左转之类的,Agent需要有后续继续理解自然语言的能力。 * Dialogue:要求agent可随时对话交互,主动用自然语言去问我们问题。目前,大多数的 Dataset 都集中在 Initial Instructions。这有几个原因了,一是创建 Dataset 的过程会比较简单,第二 Evaluation 也会相对比较简单,因为如果需要后续的 Oracle Guidance 和 Dialogue,agent 需要 Evaluate 的能力会更多就不止是是否到达终点或者找到目标物体,还有语言评估。目前 VLN 数据集非常少并且小,需求远远不够,属于数据稀缺领域(低资源模型,Low resource model)
Task Objective:
* Fine-grained:即开始给agent的指令是非常详细的,它只要按照给定的命令执行就可以,例如,先左转去到楼梯并上楼,然后右转去到厨房拿一个苹果。 * Coarse-grained:这里不会给agent详细的指令,例如拿一个苹果给我。 * Navigate and Object Interaction:为了完成任务,agent不仅仅需要Navigate,也需要做交互。例如我们要求agent去厨房里拿一些切开的苹果,但是它没有找到切开的苹果,只找到了完整的苹果,这时候,光靠Navigation是没有办法完成这个任务的,它需要拿一把刀,去执行和环境交互的动作,把苹果切开。评价指标:
* Goal-oriented Metrics:面向目标,评估agent与目标的接近程度 * Success Rate (SR):最直观,衡量距离目标一定距离内完成任务的频率 * Goal Progress(GP):衡量距离目标的剩余距离的减少 * Success weighted by Path Length(SPL):平衡成功率和路径长度- Path-fidelity(准确性) Metrics:评估 agent 遵循指令路径的程度。有些任务要求代理不仅要找到目标位置,还要遵循特定的路径。
- Coverage weighted by LS(CLS):通过路径长度得分的加权覆盖率
- Normalized Dynamic Time Warping (nDTW):动态时间序列扭曲匹配,衡量两条路径之间的相似程度
Representation Learning:帮助Agent更好的对多模态信息进行理解
* 1.Pretraining :目前用的很多且有效,VILT、VILBERT * 2.Semantic(语义) Understanding:提取模态内部的规律或者模态之间的规律和特征加强信息。 * 3.Graph Representation:感觉有点像SLAM,即时定位与地图构建,agent每走一步获取新的信息用图的方式来联系表达,图神经网络GNN * 4.Memory-augmented Model:记录历史信息并充分利用。因为VLN输入信息非常多,例如说过去的所有动作、对话交互,以及视觉内容都对以后的action有帮助,但是效率应该会降低,占用空间大,而且所有的信息可能反而存在噪音干扰信息误导agent。 * 5.Auxiliary Tasks:解读过去的动作,评估导航的进度,预测下一步方向,评估轨迹和文本的一致性,这些额外的辅助训练信号帮助agent更好地获得了活动和环境中的语义信息。Strategy Learning:帮助agent进行action
* 1.Reinforcement Learning:不像围棋,不好定义reward奖励某些行为或惩罚某些行为 * 2.Exploration during Navigation:agent先随机探索,看完周围环境Agent再决定走哪里 * 3.Navigation Planning:即提前计划并预测后面应该如何移动。 * 4.Asking For Help:Data Centric Learning:
是目前VLN非常有效的方法,因为目前VLN太过复杂,涉及的信息太多,vision、language和action这些信息都要求理解,同时信息还是动态的,然后输出一个动作。目前这种数据极度稀缺的情况下,Data-centric Learning发挥的作用非常大。- 1.Data Augmentation:可以根据已有的数据集生成路径和对应的自然语言描述,也可以先增强环境,当有更多的虚拟环境之后,再在其中建造更多的路径,例如 House3D,Matterport3D,谷歌街景等等
- 2.Curriculum Learning:训练策略,让模型先从容易的样本开始学习,并逐渐进阶到复杂的样本和知识。
- 3.Multitask Learning:同时学习多个任务,任务之间互相帮助,提高模型性能
- 4.Instruction Interpretation:换一种表达方式或者多次解释帮助 agent 更好理解指示命令。



