LLM-Blender:Ensembling Large Language Models with Pairwise Ranking and Generative Fusion
本文是论文LLM-Blender:Ensembling Large Language Models with Pairwise Ranking and Generative Fusion的阅读笔记和个人理解。
首先介绍论文中提出的一些概念
LLM Blender:集成多个 LLMs 的不同优势获得更好的性能。集成学习。总体思想就是 PAIRRANKER 比较来自 N 个 llm 的输出,然后 GENFUSER 从排名前 K 的输出生成最终输出。LLM Blender 由 PAIRRANKER 和 GENFUSER 组成。
PAIRRANKER:成对比较方法来区分候选输出之间的细微差异,用交叉注意编码器确定优选文本
GENFUSER:合并排名最高的候选答案,通过利用他们的优势和减轻弱点来产生更好的答案
具体来说每个 LLM 在不同的问题下都会产生不同的回答,例如,你问感冒了怎么办,每个 LLM 都会回答一个答案,然后可以得出一个最好的答案并记录,比如百度的文心一言,虽然总体能力没有 GPT-4 强,但在中国传统文化,写诗,韵脚,一些通假字等中文能力更强,在综合多个 LLM 的回答后选出最优的,不管哪方面的问题,都能有很好的鲁棒性。
摘要
我们介绍了 LLM-BLENDER,这是一个集成框架,旨在通过利用多个开源大型语言模型(llm)的不同优势来获得持续的卓越性能。我们的框架由两个模块组成:配对器和基因器,解决了不同例子的最佳 llm 可能显著不同的观察。成对器采用一种专门的成对比较方法来区分候选输出之间的细微差异。它联合编码输入文本和一对候选文本,使用交叉注意编码器来确定优选文本。我们的结果表明,配对排序者与基于 chatgpt 的排名的相关性最高。然后,GENFUSER 旨在合并排名最高的候选人,通过利用他们的优势和减轻他们的弱点来产生更好的产量。为了方便大规模的评估,我们引入了一个基准数据集,Mix 指示,它是一个具有 oracle 成对比较的多个指令数据集的混合。我们的 llm 混合器在各种指标上显著优于单个 llm 和基线方法,建立了一个巨大的性能差距。
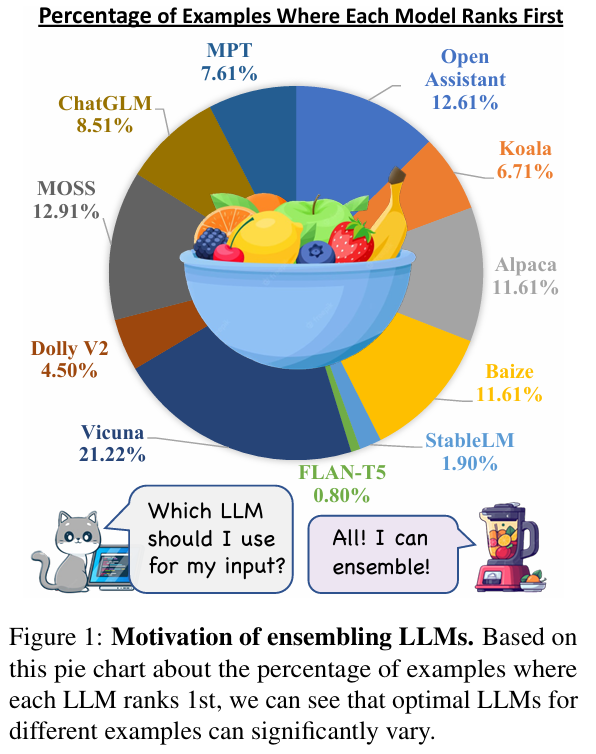
ensemble LLM的motivation,最优LLM不同的例子有很大的不同
LLM-Blender
我们提出了一个秩和保险丝的管道框架,llm-blender,用于集成 llm,如图 2 所示。该框架由两个主要组件组成:一个成对排序模块,成对排序器(第 3 节),和一个融合模块,genfuser(第 4 节)。配对者模块学习为每个输入比较所有候选对,然后对候选列表进行排序。然后我们选择排名前 K = 3 的候选序列,将它们与输入 x 连接,并构建基因用户模块的输入序列。GENFUSER 模块,一个 seq2seq LM,最终生成最终输出,为用户服务。
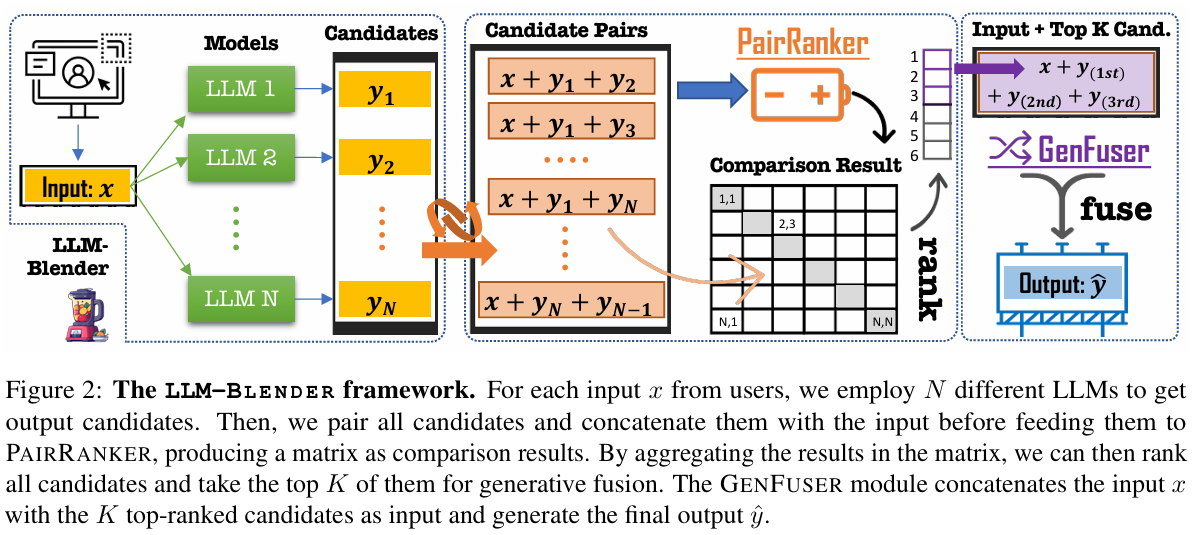
LLM-Blender的框架图
他的思路很巧妙,成对的去进行比较训练,有 N 个 LLM,那两互不相同的输出就有 N (N-1)/2 个(N-1 加到 1 的等差数列),然后一个输入两个输出去训练(一般都是一个输入,一个输出),然后去训练一个模型,使得预测的时候一个输入获得一个输出,他这种用两个输出的方式就可以学习到二者的差异。它实现的方式也很简单,就是在 embedding 的时候分别把 x 和 yi 和 yj 进行 concate 拼接,得到最后可以得到一个聚合矩阵作为比较结果,然后就可以排序选出 topk 个作为最后的输出



