Multimodal Large Language Model 总结
由于最近论文工作需求,本文以总结的形式梳理了近期比较有代表性的MLLM, 推荐有基础后再阅读Revolution of Visual-Language Adapter
目前的MLLM基本组成有三部分, Visual Backbone, V-L Adapter, LLM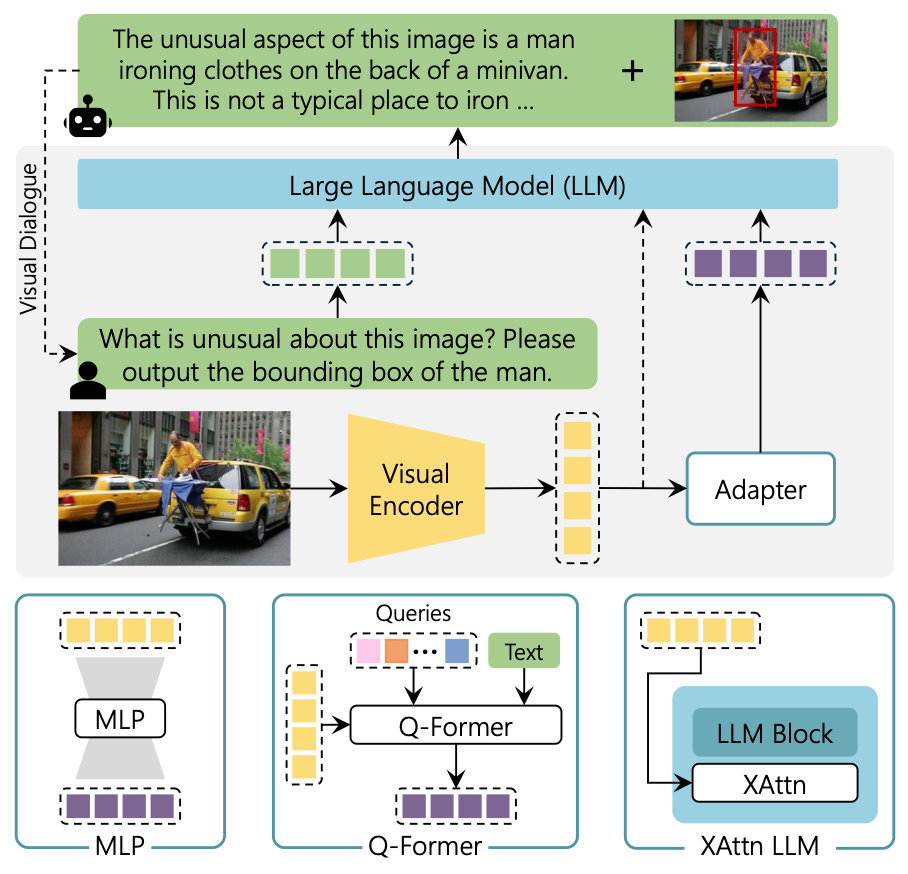 大多数MLLM基本在LLM内部没有什么变化, Visual Encoder基本也用的CLIP的Vision Encoder, 主要区别在于Adapter上
大多数MLLM基本在LLM内部没有什么变化, Visual Encoder基本也用的CLIP的Vision Encoder, 主要区别在于Adapter上
Flamingo
论文: Flamingo: a Visual Language Model for Few-Shot Learning. Flamingo代表了在LLM主干中加入Cross Attention从而用视觉增强文本表示的一派.Flamingo 将视觉信息融入 LLM 的方式是在 LM Block 的主干上串行的加入一个用 Cross Attention 增强文本表示的模块,从而让文本表示中能融入视觉信息
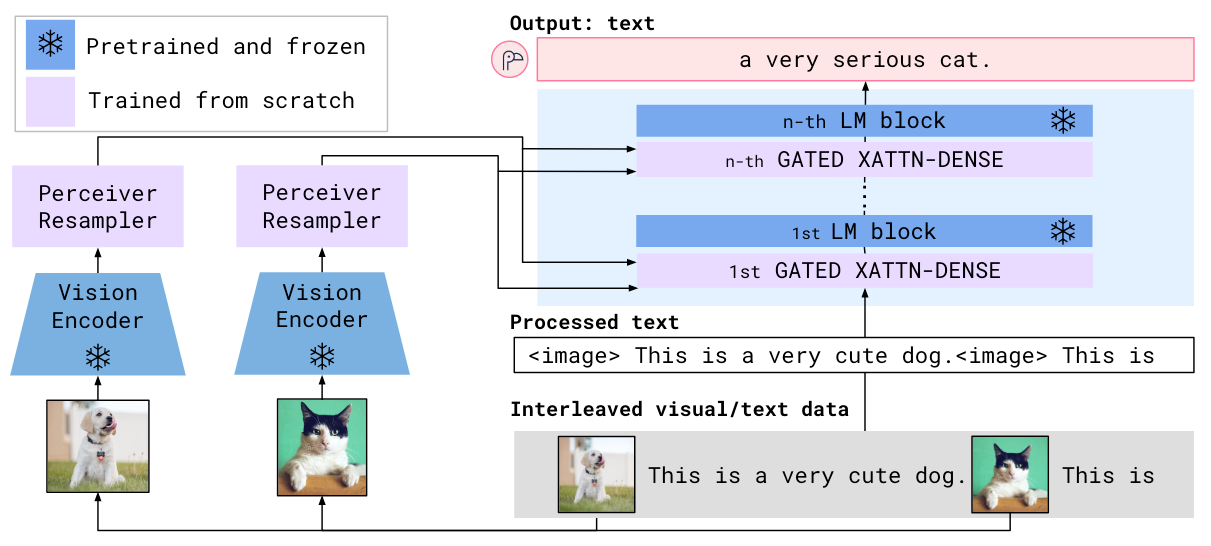
V 预训练 LM 为 Chinchilla 1.4 / 7 / 70B.
作者在每个 LM Block 前面加上了一个 Gated Cross - Attention Block. 以 Language 为 Query, Vision input 为 Key 和 Value, 并用 Tanh 和残差做一下过滤,决定视觉增强的文本表示流通率的门控系数为全 0 初始化,跟 LoRA 有点类似.
比较有趣的是作者提到了 Flamingo 对交错图文 (Interleaved Image Text) 的数据的处理方法
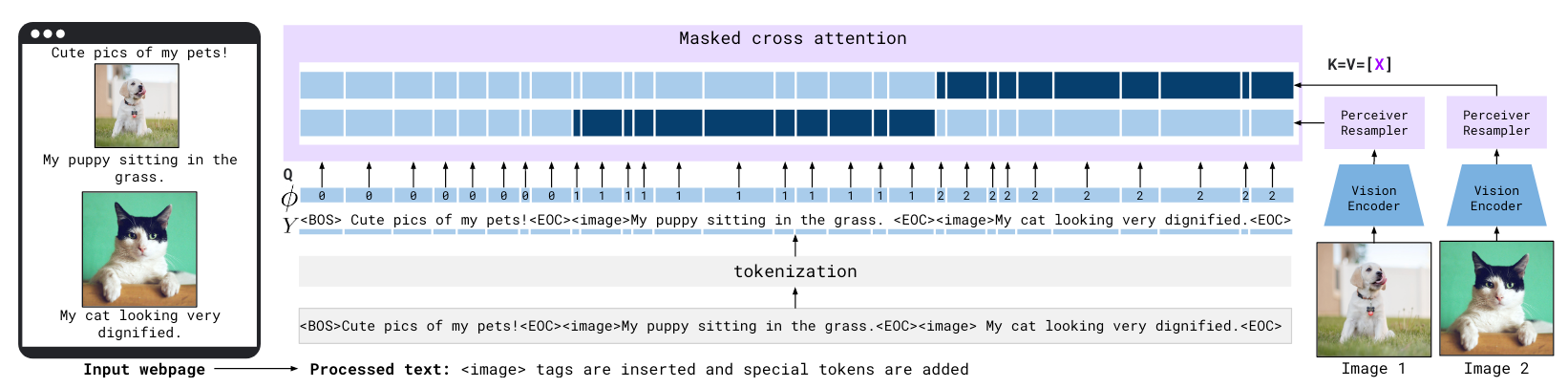
在一系列文本和一系列图像构成的图文交错数据中,每个文本块中 Token 在 Cross - Attention 中只能对对应的 Visual Token 做 Attention (深蓝色), 而无法对其他 Visual Token 做 Attention (浅蓝).
在作者的实验中,将作者构建的交错图文数据集去掉后,模型效果下降非常严重。也许交错图文是一个 Tricks
BLIP-2
BLIP-2开创了以VL对齐的Q - Former抽取视觉信息送给LLM的先河 论文:BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language ModelsBLIP-2 提出的背景: 当前大规模模型在预训练期间的高额计算消耗太大,数据也用的特别多。作者引入一个 lightweight Querying Transformer (Q - Former) 来完成 Visual & Language 模态的桥接过程
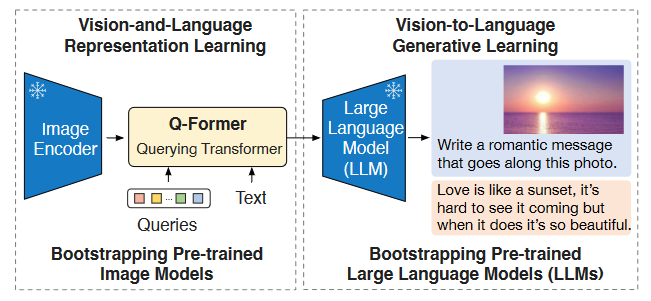
作者把 Q - Former 的训练拆分为两个阶段:
- 首阶段:让 Q - Former 从 Freeze Image Encoder 中学习 VL 表示.
- 次阶段:从 Freeze LLM 中学习 VL 表示.
Q - Former 结构和首阶段预训练如下
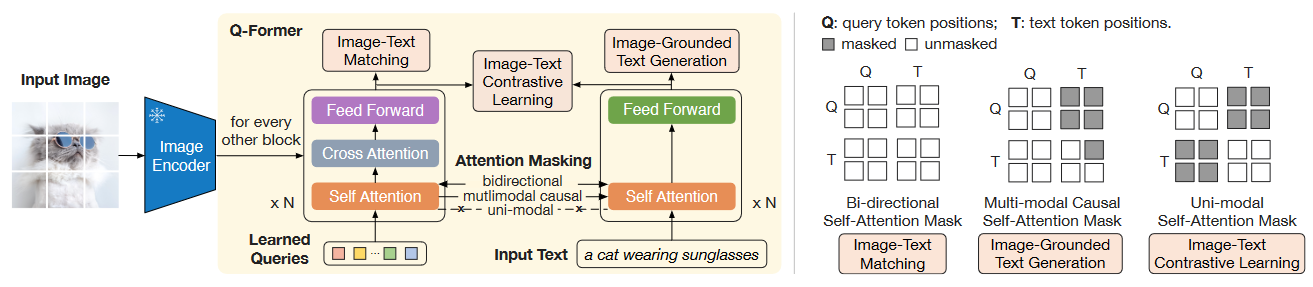
Q - Former 实际上由双塔的两个 Transformer 组成,分别被称为 Image Transformer 和 Text Transformer.
由于在首阶段中 Q - Former 已经完成了 Query 从 Image Encoder 中抽取关键信息的学习,这也就使得 Visual Signal 可以被 Query 以 Soft Visual Prompt 的形式传递给 LLM. 所以 Q - Former 中的 Text Transformer 变得不再必要,可以被丢弃. Query 表示还需要过一层 Linear Project 和大模型输入维度对齐.
InstructBLIP
论文:InstructBLIP: Towards General-purpose Vision-Language Models with Instruction Tuning 延续BLIP-2的Q - Former, 在Q - Former中添加了Instruct, 从而使得Q - Former能完成Instruction-aware Visual Feature Extraction, 从而将Visual Feature从静态的变为动态的, 能够做到instruction following,其余细节基本一致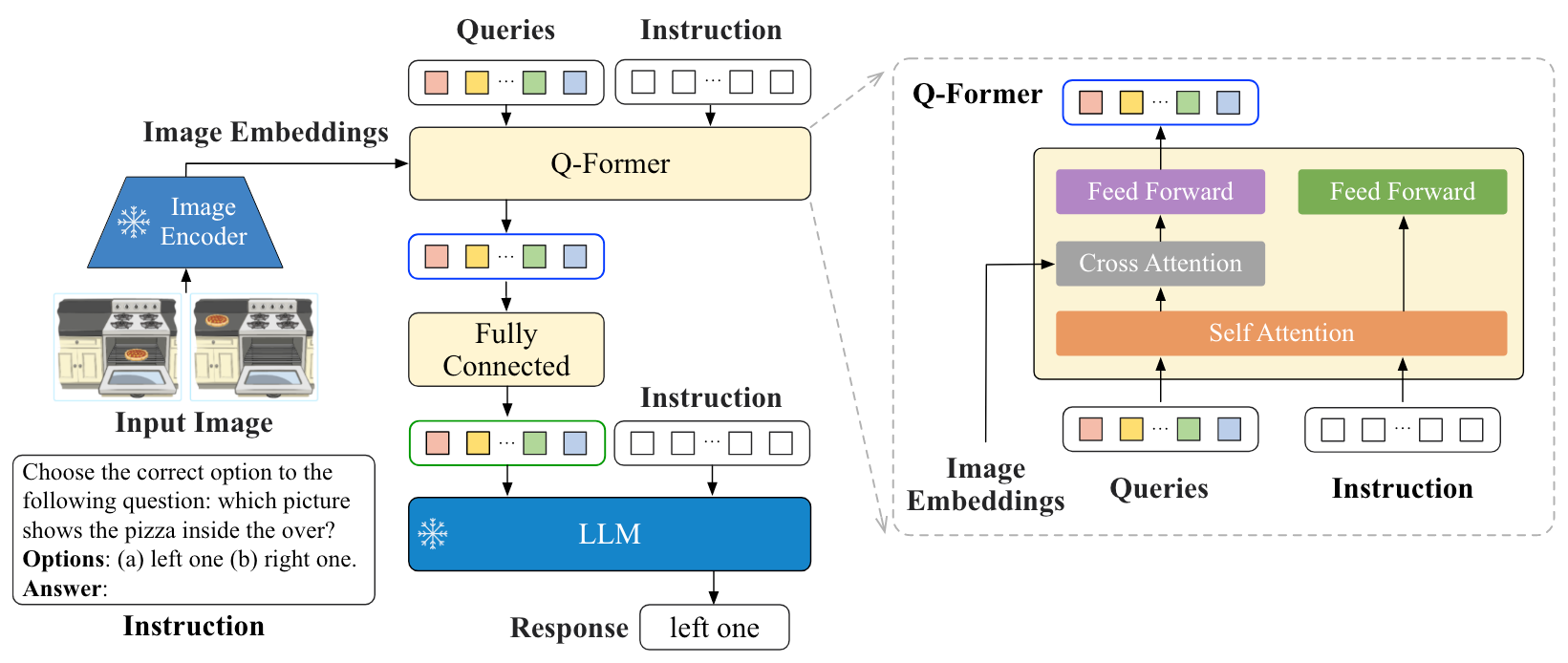
与之类似的还有同样为 BLIP 系列续作的 X-InstructBLIP, 但审稿人似乎认为这种方法并没有具备很大的贡献,以及实验不够充分缺乏与当前的 MLLM 对比,于是在 ICLR 24 被拒稿了.
LLaVA
LLaVA代表了整个使用MLP为Adapter的一派论文:Visual Instruction Tuning
与 BLIP-2 的 Q - Former 不同,LLaVA 抛弃了沉重的 Visual Extractor 设计
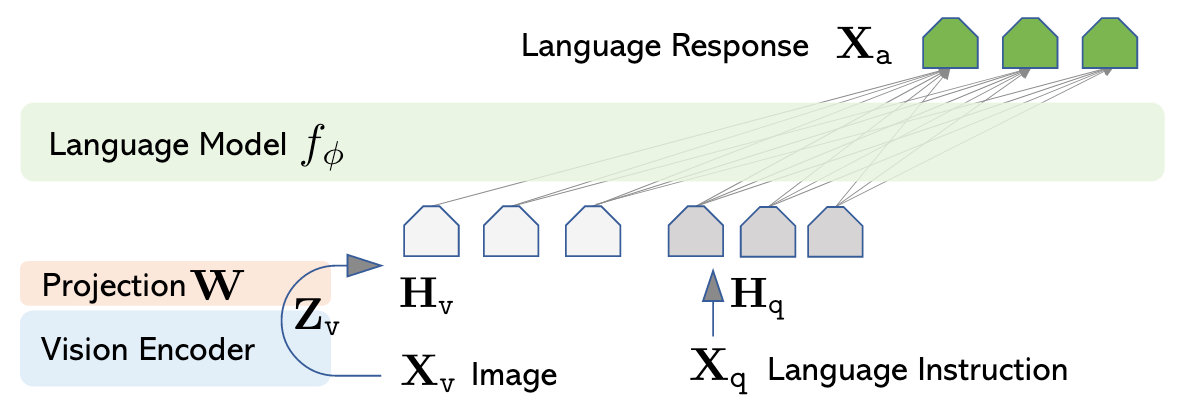
用预训练的 CLIP 抽取的 Visual Feature 作为 Vision Signal, 再用一次 Linear Projection 后送到 LLM 里面. LLaVA 训练的时候遵循多轮对话
作者设计了两阶段微调,让 LLM 能适配 Visual Input:
- Stage 1: Pre - training for Feature Alignment, 只调 Linear Projection 的参数,使 Visual Feature 和 LLM Embedding Space 对齐.
- Stage 2: Fine - tuning End-to-End, 让 Linear Projection 和 LLM 一起调.
比较有意思的是,LLaVA 的指令数据集是用 LLM (ChatGPT / GPT4) 生成的,通过把图像中的信息以自然语言描述出来从而传递给更高阶的 LLM, 让 LLM 生成指令数据.
LLaVA-1.5
论文:Improved Baselines with Visual Instruction Tuning
LLaVA 1.5 是 LLaVA 的改进版本
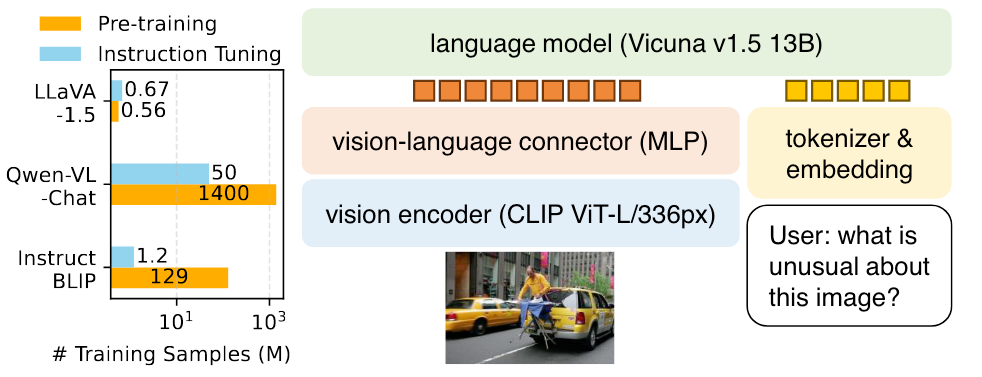
主要做了如下改动:
- 限制了 LLM 的输出格式,让 LLaVA 直接以简短的方式回答,有利于 VQA 任务.
- 从一层 Linear Project 变成了两层 MLP.
- 加入了学术方面的数据集,用于解锁 LLaVA 对视觉区域细粒度理解能力.
- 提高了图像分辨率,并加入了额外数据源.



